8 minutes
NVMe에서 iostat의 높은 %util 값 (RHEL/CentOS 7.6)
- 안내: 이 글을 읽기 전에 [Linux iostat] 문서를 먼저 읽어주시기 바랍니다.
- 버전: 2019/03/22 (수정), 2019/01/28 (초안)
최근 NVMe와 같이 디스크 장치에서 병렬처리가 가능한 제품을 사용 할 때에 iostat의 지표 값이 이상하다는 이야기가 많습니다. 잘 알려진 내용으로는 Linux iostat에서 소개하고 있는 내용처럼 svctm 지표 자체가 제대로 계산되지 않아서 제 성능을 내기도 전에 100%의 Utilization 지표를 나타내는 이슈가 있습니다.
다만, 최근 RHEL/CentOS 7.6에서 동일하거나 유사한 수준의 I/O 처리에 대해서 기존 7.4와 달리 iostat 값의 %util 지표가 100%에 가깝게 나타난다는 제보를 받고 관련 된 내용을 확인해 보았습니다.
svctm
먼저, iostat에서 svctm은 서비스 처리시간을 의미하는 지표입니다. 앞서 소개했던 글에서 자세히 설명해 준 것 처럼 해당 지표는 과거 단일 I/O 스케줄러에 의해서 관리 될 때에만 의미가 있지 지금과 같은 Multi-Queue 환경이나 병렬처리 환경에는 의미가 없습니다.
sysstat 프로젝트에서 이미 버전 10에서 매뉴얼 페이지에서 svctm 지표에 대해서 아래와 같이 신뢰하지 말라고 소개하고 있으며 향후 버전에 삭제 된다는 말처럼 최신 버전 12에서는 해당 지표는 존재하지 않습니다.
svctm
The average service time (in milliseconds) for I/O requests that were issued to the device. Warning! Do not trust this field any more. This field will be removed in a future sysstat version.
%util
최근 iostat의 매뉴얼 페이지에서 %util 지표를 아래와 같이 소개하고 있습니다.
%util
Percentage of elapsed time during which I/O requests were issued to the device (bandwidth utilization for the device). Device saturation occurs when this value is close to 100% for devices serving requests serially. But for devices serving requests in parallel, such as RAID arrays and modern SSDs, this number does not reflect their performance limits.
I/O 처리요청의 발생에 따른 소요 시간의 비율로 해당 값이 높으면 높을 수록 I/O 처리에 많은 시간을 소요한 것처럼 보일 수 있습니다. 하지만, 매뉴얼에서 설명하는 것 처럼 병렬처리가 가능한 경우에는 제대로 된 연산이 안되기 때문에 100% 이상이 나올 수 있도록 표기한다면 NVMe와 같은 장치에서는 수백%의 지표로 표기도 가능할 것입니다.
즉, sysstat 프로젝트에서도 인지하고 있는 것 처럼 익히 알고 있던 iostat의 %util 지표는 병렬처리와 멀티큐가 가능한 환경에서 더 이상은 부하의 지표로 삼기 어렵다는 이야기가 됩니다.
배포판 버전에 따른 지표 차이
초반에 이야기 했던 CentOS 7.6에서 7.4와 다른 지표를 보이는 문제에 대해서 이야기해보면 iostat이 연산을 위해서 참고하는 정보를 확인해 볼 필요가 있습니다.
iostat은 %util 계산을 위해서 /proc/diskstats 파일을 참조합니다. 이 파일의 항목 중에서 %util과 관련이 있는 부분은 I/O 처리에 소요된 시간(ms) 값 입니다. (참조: /proc/diskstats)
이 값의 변화를 간단한 스크립트로 작성해서 1초마다 기록해보면 7.4와 7.6에서 아래오 같은 차이를 보이고 있었습니다.
[CentOS 7.6]
diff: 956
diff: 976
diff: 982
......
[CentOS 7.4]
diff: 9
diff:12
diff: 13
......
동일한 수준의 I/O에 대해서 해당 값의 변화폭이 너무커서 결과적으로 7.6 버전에서는 iostat의 %util 값이 100%에 가깝게 표기되는 것을 알 수 있었습니다.
blk-mq
병렬처리가 가능한 하드웨어가 등장함에 따라 Linux 커널도 Block I/O Layer의 구조가 바뀌었습니다. 기존에는 I/O Scheduler에 따라서 처리되던 Block Layer에 Multi-Queue가 적용 되었습니다. 이를 blk-mq라고 합니다. blk-mq에 대한 자세한 내용은 아래 내용을 참고하세요.
- Improvements in the block layer LWN.net
- [Linux Multi-Queue Block IO Queueing Mechanism (blk-mq) - Thomas-Krenn-Wiki]
- blk-mq scheduling framework LWN.net - Patchiset
- Add support for multiple queue maps LWN.net - Patchset
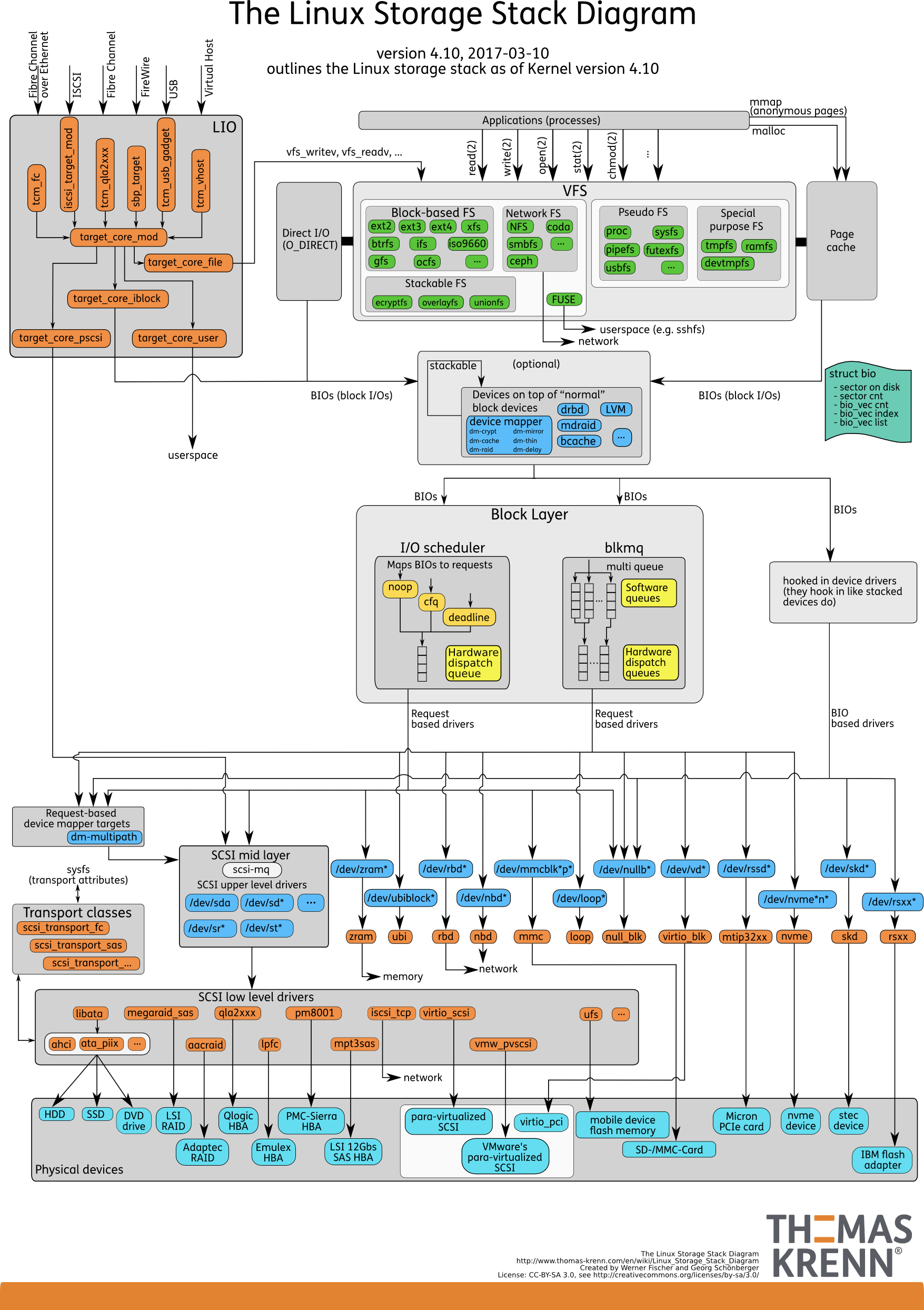
- 출처: thomas-krenn
blk-mq 프레임워크가 커널에 적용되었고 이를 활용하는 드라이버 들이 생겨났습니다. (ex. nvme) 따라서 모든 CPU 코어에 개별적인 I/O Queue를 할당하고 I/O 성능을 개선 할 수 있게 되었습니다.
하지만, 드라이버와 달리 I/O 스케줄러는 상대적으로 늦게 준비되었습니다. 그렇기 때문에NVMe의 경우에는 일반적으로 I/O 스케줄러가 적용되지 않습니다. 보통은 sysfs에서 확인 할 수 있는 I/O 스케줄러 (elevator) 정보가 none으로 표기 됩니다. (none은 noop과 다르며 I/O 스케줄러를 거치지 않는 다는 이야기 입니다)
$ cat /sys/block/nvme0n1/queue/scheduler
none
Multi-Queue I/O Scheduler
RHEL Release note를 보면 7.2에서 blk-mq에 대해서 소개하고 있습니다. 다만, PCI 장치들에 대한 blk-mq 커널 config 옵션은 7.5 릴리즈 커널부터 포함되었습니다. 그리고 이 시점에 Multi-Queue를 지원하는 I/O Scheduler를 포함시켰습니다.
CONFIG_POSIX_MQUEUE=y
CONFIG_POSIX_MQUEUE_SYSCTL=y
CONFIG_BLK_MQ_PCI=y
CONFIG_MQ_IOSCHED_DEADLINE=y
CONFIG_MQ_IOSCHED_KYBER=y
따라서, 7.5 릴리즈 커널(3.10.0-862)에서는 sysfs 정보를 보면 mq-deadline과 kyber 스케줄러가 추가되어있습니다.
$ cat /sys/block/nvme0n1/queue/scheduler
[none] mq-deadline kyber
none. none?
다시 이슈가 된 이유로 돌아가 보면 7.5 릴리즈 부터 추가 된 blk-mq를 지원하는 스케줄러와 별개로 과거부터 계속해서 none으로 설정하여 I/O Scheduler를 별도로 적용하지 않았음에도 7.4와 7.6에서 /proc/diskstats의 지표는 차이가 있었습니다. (이 값은 sysfs의 각 블럭 디바이스 stat 정보입니다. ex. /sys/block/nvme0n1/stat) 이에 7.4 릴리즈부터 7.6 릴리즈까지의 커널의 변경 점에 대해서 찾아본 결과 blk-mq와 관련 된 220여개 이상의 패치 사항이 있었으며 그 중 눈여겨 볼 만한 아래와 같은 내용을 확인 할 수 있었습니다.
- [block] blk-mq: issue directly if hw queue isn't busy in case of 'none' (Ming Lei) [1599682]
- [block] blk-mq: fix sysfs inflight counter (Ming Lei) [1548261]
- [block] blk-mq: count allocated but not started requests in iostats inflight (Ming Lei) [1548261]
- [block] blk-mq: enable checking two part inflight counts at the same time (Ming Lei) [1548261]
- [block] blk-mq: only attempt to merge bio if there is rq in sw queue (Ming Lei) [1597068]
- [block] blk-mq: update nr_requests when switching to 'none' scheduler (Ming Lei) [1585526]
- [block] blk-mq: set mq-deadline as default scheduler for single queue device (Ming Lei) [1154525]
- [block] blk-mq: introduce request_aux (Ming Lei) [1458104]
blk-mq 관련 버그적인 수정사항도 있지만 로직과 카운팅에 대한 수정 사항도 있었습니다. 따라서, none으로 설정하여 사용하던 NVMe 장치에 대해서는 커널에서 기본 스케줄러로 blk-mq를 적용하고 있으며 blk-mq의 카운팅 방식에 따라서 해당 수치의 변화가 발생했다고 보여집니다. (가장 영향이 크다고 보여지는건 inflight에 대한 카운트 및 측정이지만 커널 패치 설명이 명확하지 않아 조금은 모호한 부분도 있습니다) 패치내용에 Legacy가 의도한 바대로 맞췄다는 얘기도 있지만 과연 이게 바람직한 것인지 까지는 판단하기 어렵습니다.
2019/03/22 추가
- 이 부분이 바람직한지에 대한 의문이 있었는데 박지훈님의 제보로 RedHat에서 이를 문제로 인지하고 조만간 수정 할 계획이라는 문서가 확인되었습니다. (iostat -x and sar -d output shows incorrect high %util values for nvme SSD disks - Red Hat Customer Portal)
- 위 수정사항이 반영되면 none 상태에서도 지표가 기존처럼 기대한 수치로 나올 것으로 보입니다.
즉, 결과적으로 blk-mq의 변화에 따라서 /sys/block/장치/stat, /proc/diskstats 값의 차이가 발생했다고 볼 수 있으며 이를 확인 할 수 있는 방법으로 커널 버전을 바꾸지 않더라도 NVMe 디스크를 LVM으로 사용하고 dm에 Multi-Queue(blk-mq)를 사용하지 않는 경우(dm_mod.use_blk_mq=n 인 경우이며 기본 값 입니다) 기대하는 stat(/proc/diskstats)값을 볼 수 있습니다. 마찬가지로 iostat에서 개별 파티션의 상태를 확인해도 기대하는 %util 값을 확인 할 수 있습니다. 아래는 LVM 구성을 한 서버에서 개별 파티션 정보까지 iostat으로 확인 한 내용입니다.
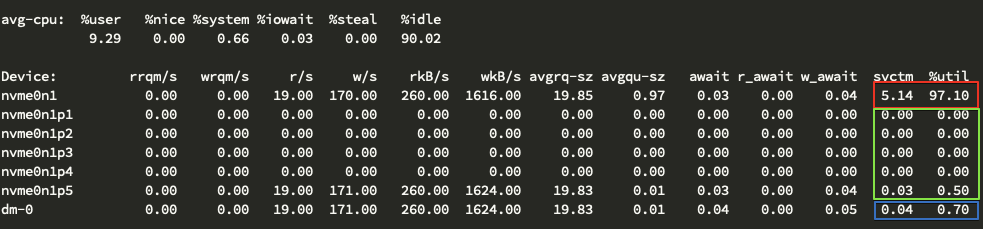
위 결과에서 보이는 것 처럼 svctm, %util 항목에서 dm-0와 NVMe 개별파티션의 합이 NVMe 장치에 대한 지표와 일치 하지 않는 것을 볼 수 있습니다.
mq-deadline, kyber
앞서 언급한 Multi-Queue I/O 스케줄러(elevator)가 새롭게 추가 되었기 때문에 blk-mq에 맞춰서 제공되는 해당 스케줄러를 적용해보면 sysfs의 stat과 proc의 diskstats 지표가 기대하는 형태로 바뀌게 되는 걸 확인 할 수 있습니다.
$ echo 'mq-deadline' > /sys/block/nvme0n1/queue/scheduler
$ iostat -x -p ALL 1
avg-cpu: %user %nice %system %iowait %steal %idle
8.25 0.00 0.78 0.03 0.00 90.93
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
nvme0n1 0.00 0.00 21.00 169.00 184.00 1488.00 17.60 0.00 0.01 0.05 0.01 0.01 0.20
nvme0n1p1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
nvme0n1p2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
nvme0n1p3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
nvme0n1p4 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
nvme0n1p5 0.00 0.00 21.00 169.00 184.00 1488.00 17.60 0.00 0.01 0.05 0.01 0.01 0.20
dm-0 0.00 0.00 21.00 169.00 184.00 1488.00 17.60 0.00 0.02 0.05 0.01 0.01 0.20
$ echo 'kyber' > /sys/block/nvme0n1/queue/scheduler
$ iostat -x -P ALL 1
avg-cpu: %user %nice %system %iowait %steal %idle
9.16 0.00 0.82 0.00 0.00 90.02
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
nvme0n1 0.00 0.00 24.00 160.00 208.00 1568.00 19.30 0.00 0.03 0.00 0.03 0.02 0.40
nvme0n1p1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
nvme0n1p2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
nvme0n1p3 0.00 0.00 0.00 1.00 0.00 4.00 8.00 0.00 0.00 0.00 0.00 0.00 0.00
nvme0n1p4 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
nvme0n1p5 0.00 0.00 24.00 159.00 208.00 1564.00 19.37 0.00 0.03 0.00 0.03 0.02 0.40
dm-0 0.00 0.00 24.00 159.00 208.00 1564.00 19.37 0.00 0.02 0.00 0.03 0.02 0.40
blk-mq에 맞는 I/O Scheduler 사용이 필수?
blk-mq를 지원하는 커널에서 none을 사용하게 될 때와 mq-deadline과 같은 blk-mq 지원 스케줄러를 사용 할 때 지표의 차이가 발생하는 부분은 blk-mq에 적합한 형태의 스케줄링 알고리즘이 적용되어서라고 볼 수 있습니다. 하지만, 한편으로는 직접적인 I/O Scheduler가 적용되지 않더라도(none) blk-mq에서 적절히 카운팅해서 처리한다면 이러한 혼동을 예방할 수 있을텐데 왜 이러한 형태로 지표를 제공하는지 의문스럽긴 합니다.
다만, sysstat 프로젝트에서도 svctm과 %util 지표에 대해서 더 이상 사용하지 않거나 신뢰하지 말라고 얘기하기 때문에 (svctm을 삭제한 것 처럼 %util도 삭제하는게 혼선을 줄이는 방법일 수 있겠지만 여전히 일반 HDD 타입은 존재) 모니터링 하는 입장에서 NVMe 디스크 장치의 부하(saturation)를 확인 할 적절한 지표를 마련하는 것은 필요하다고 봅니다.
모니터링 지표의 방법으로는 아래와 같은 방안을 검토 해 볼 수 있습니다.
- 3월 22일 추가 - blk-mq / none 상태에 대한 수정이 적용되면 기존 방식대로 모니터링 결과를 얻을 수 있을 것으로 보입니다. 다만, sysstat 프로젝트에서 svctm과 %util에 대한 신뢰도 부분을 얘기하고 있기 때문에 향후에도 계속 이를 절대적 지표로 보긴 어렵기 때문에 대안 마련도 필요해 보입니다.
- mq를 지원하는 I/O Scheduler의 사용 디스크 타입에 맞추어 스케줄러 존재 여부를 체크하고 적용하는 시스템적 처리가 필요합니다 mq를 지원하는 I/O Scheduler의 벤치마크를 통해서 지표 개선 뿐만 아니라 성능 개선에 대해서도 검토해 볼 수 있습니다. (참고 링크의 벤치마크 정보 참조)
- 실제 사용하는 디스크 볼륨에 대한 iostat 지표 사용 파티셔닝해서 사용하는 경우에는 개별 파티션에 대한 지표를 사용 LVM/RAID를 사용하는 장치에 대해서는 DM 장치에 대한 지표를 사용
- Read tick과 Write tick 값을 별도로 취해서 지표로 사용 (sysfs/block/
/stat, proc/diskstats 공통)
참고 할 만한 링크
- sysfs/stat
- proc/diskstats
- Red Hat Enterprise Linux 7 Chapter 14. Storage - Red Hat Customer Portal
- 2⁄2 blk-mq: fix sysfs inflight counter - Patchwork
- github: blk-mq-pci
- Two traps in iostat: %util and svctm - Marc’s Blog
- Understanding iostat
- Linux 4.17 I/O Scheduler Tests On An NVMe SSD Yield Surprising Results - Phoronix
- Two new block I/O schedulers for 4.12 LWN.net
- Block layer introduction part 2: the request layer LWN.net
- blk-mq: Introduce combined hardware queues LWN.net
- Ubuntu I/O Schedulers
- Performance Analysis of NVMe SSDs and their Implication on Real World Databases - PDF
- diskstats plugin reports near 100% usage for NVME drives
- Archlinux - Improving performance
- ORACLE UEK 4 : Where is my I/O scheduler ? None ? Multi-queue model blk-mq | Hatem Mahmoud Oracle’s blog
- Why %util number from iostat is meaningless for MySQL capacity planning
- Linux Multi-Queue Block IO Queueing Mechanism