16 minutes
NUMA with Linux
개인 위키에서 정리하던 내용을 블로그로 옮긴 것 입니다. 이 문서는 NUMA 아키텍처에 대한 간략한 소개와 Linux에서의 활용 방법에 대해서 소개하고 있습니다.
1. System Topology
1-1. CMP
최근 CPU는 하나의 소켓에 여러개의 코어를 가지고 있다. 이를 보통 멀티코어라고 지칭하며 하나의 칩에 여러개의 프로세서가 올라가기 때문에 CMP(Chip-level Multi Processor)라고도 부른다. 이러한 멀티코어 CPU에 대한 메모리 관계는 아래와 같이 표현 할 수 있다.
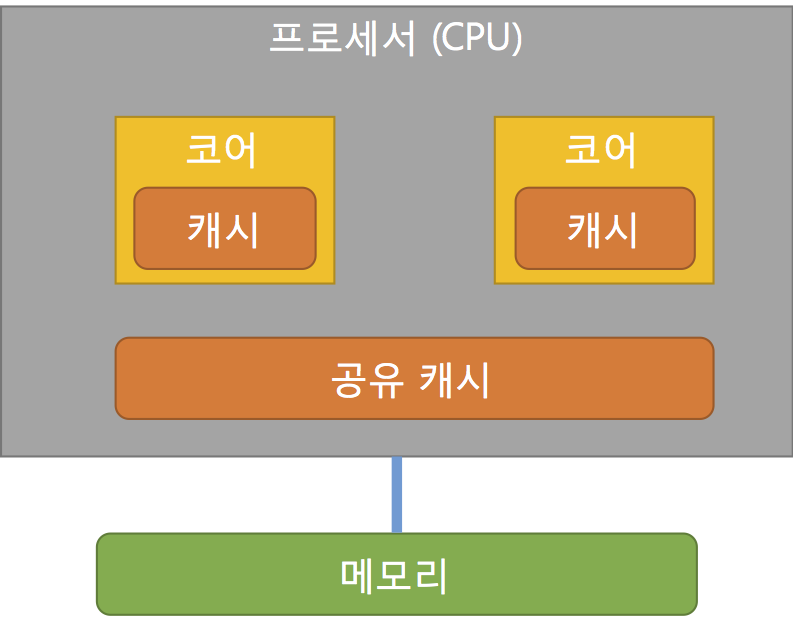
1-2. SMP
하지만, 멀티코어 CPU를 2개 이상 장착한 시스템의 경우에는 메모리를 2개 이상의 CPU가 접근하기 때문에 CPU와 메모리 사이를 네트워크로 묶어서 접근이 필요하며 아래와 같이 표현이 가능하다. 이를 SMP(Symmetric Multi Processor)라고 한다.
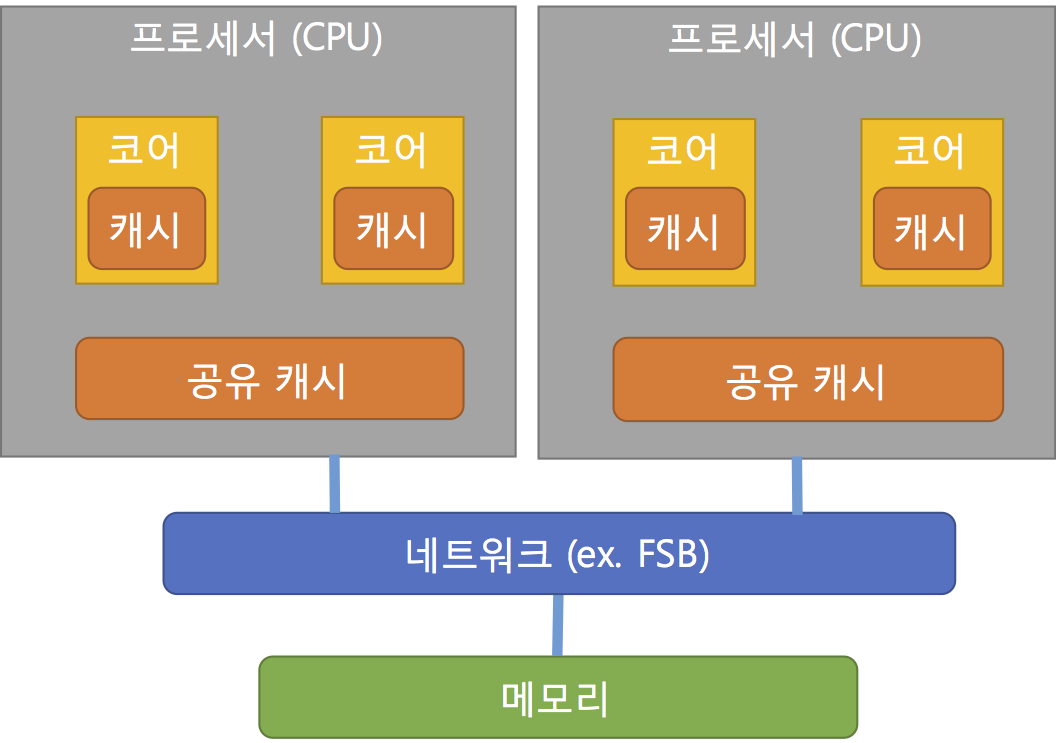
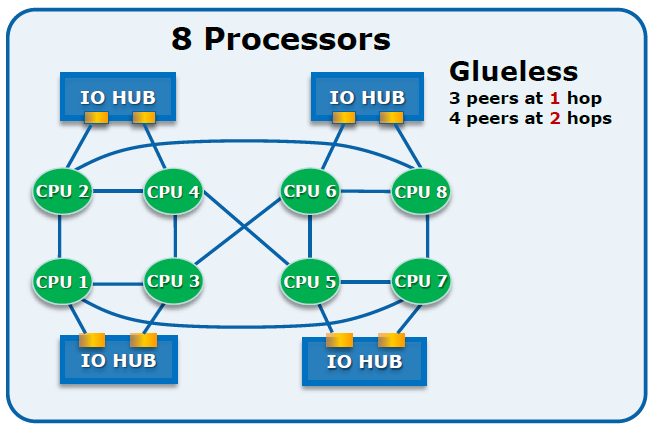
이러한 메모리접근을 위한 네트워크를 과거 펜티엄(Pentium)기반 프로세서는 FSB(Front-Side Bus)라는 방식으로 제공되었고 이를 개선하기 위해서 AMD에서는 HTT(Hyper Transport Technology)를 Intel에서는 QPI(Quick Path Interconnect)라는 기술을 통해서 보다 빠른 성능을 제공하였다. 다만, HTT나 QPI 모두 연결방식에 대한 기술이지 시스템 위상(Topology)에 대한 기술이 아니다. 예를 들어 QPI의 경우에는 Point-to-Point 양방향 연결에 대해서 빠른 속도를 제공하는 기술이기 때문에 각 장치마다의 연결점을 갖게 되고 결과적으로 많은 프로세서를 갖게 되면 이를 연결하기 위한 복잡성은 커질 것이다. (아래 그림은 실제 SMP에 QPI를 적용한 그림은 아니며 QPI 연결에 대한 예시를 위해 인용한 그림이다)
또한, SMP 구조에서는 메모리를 공유하기 때문에 한 번에 한개의 프로세서만이 동일한 메모리에 접근이 가능하기 때문에 다른 프로세서들을 대기하게 만드는 문제점이 있다. 이는 프로세서가 많아 질 수록 더 성능적인 문제점을 야기 할 수 있다. (메모리 접근은 CPU에 비해서 월등히 느리다. 즉, 메모리 접근을 대기하는 것은 큰 손실이라고 볼 수 있다.)
1-3. NUMA
그래서, 이를 개선하기 위해 나온 형태가 NUMA(불균일 기억 장치 접근, Non-Uniform Memory Access) 이며 각 프로세서가 독립적인 로컬 메모리를 보유하고 프로세서의 상대적 위치에 따라서 메모리 접근 속도가 달라지는 방식이다. 따라서, 각 프로세서는 로컬 메모리에 접근 할 경우에 다른 프로세서에 의한 대기를 하지 않아도 되고 빠른 속도로 접근이 가능하다.
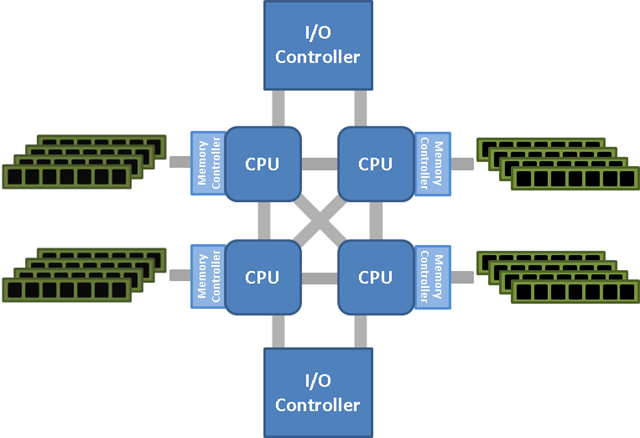
하지만, 여러 프로세서가 동시에 동일한 데이터가 필요할 경우 메모리 뱅크들 사이로 데이터를 이동하기 때문에 성능이 떨어 질 수 있다. 그렇기 때문에 무조건적으로 효율이 좋은 것은 아니므로 프로세스가 로컬메모리를 사용하도록 하는게 최적화의 키 포인트이다. 그리고 CPU에 달려있는 작은 크기의 비공유 메모리(CPU캐시라 불리우는 것)가 있는데 기본적인 NUMA 형태는 프로그래밍 상으로 공유 메모리에 대해서 캐시 일관성(Cache Coherence)을 유지하기 어렵기 때문에 대부분의 NUMA 시스템은 ccNUMA(cache-coherence NUMA)형태로 하드웨어적으로 구현하여 제공하고 있다.
1-4. Node Interleaving
NUMA에서는 프로세서에 메모리 컨트롤러가 장착되어서 로컬 메모리를 가지고 있지만 BIOS에서 이를 기존의 SMP처럼 사용하도록 설정하는 기능을 제공하고 있다. 흔히 BIOS 상에서 Node Interleaving이라는 설정 값으로 존재한다.
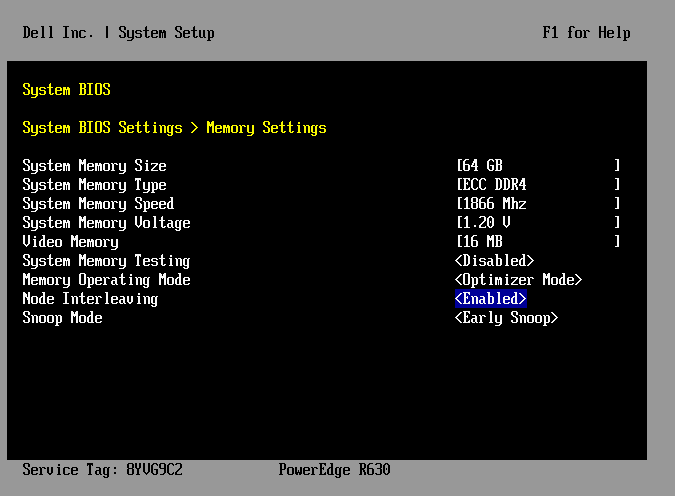
이 기능을 활성화 한다면 시스템은 노드의 모든 메모리를 하나의 연속된 메모리처럼 매핑되고 각 메모리 페이지는 RR(Round-robin) 형태로 노드에 흩뿌려지게 된다.
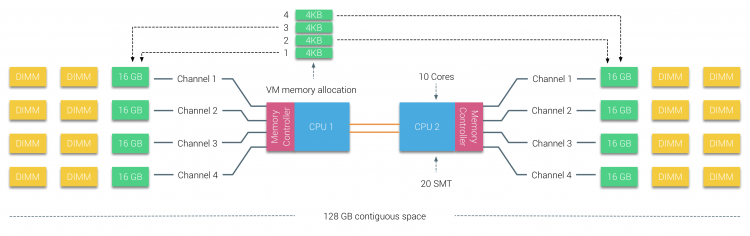
일반적인 SMP 시스템처럼 전체 메모리에 일관된 주소로 접근 할 수 있지만 이미 NUMA 구조인 시스템을 SMP처럼 흉내내기 때문에 SUMA(Sufficiently Uniform Memory Architecture)라고 불리우기도 한다. 실제로 Intel의 Memory Latency Checker로 메모리 응답 속도를 확인해 보면 아래와 같이 차이가 발생한다. 즉, SUMA의 경우 메모리 응답속도가 고른편이지만 최적의 응답속도를 제공하지는 않는다.
- Haswell 시스템에서 테스팅 한 값이며 단위는 ns

시스템에서 동작하는 어플리케이션이 NUMA 아키텍처와 잘 맞지 않거나 최적화를 통한 빠른 성능보다는 균일한 응답속도와 대량의 메모리를 SMP처럼 사용하는 환경에 더 적합하다면 Node Interleaving을 활성화 하는 것도 좋은 방법이 될 수 있다.
2. NUMA with Linux
이제 Linux에서 CPU Affinity 및 NUMA 정책을 설정하는 방법에 대해서 알아보자.
2-1. taskset
taskset 커맨드는 현재 동작중인 프로세스에 대해서 CPU Affinity를 확인하거나 지정하는 도구이다. 또한, 지정된 Affinity 값으로 프로그램을 실행 할 때도 사용 할 수 있다.
먼저 -p 옵션을 통해서 현재 프로세스의 affinity mask 값을 확인하면 아래와 같다.
$ sudo taskset -p 874
pid 874's current affinity mask: ffffff
특정 프로세스의 affinity mask를 변경하려면 아래와 같이 실행하면 된다.
taskset -p <마스크> <PID>
$ sudo taskset -p 01 16764
pid 16764's current affinity mask: 3
pid 16764's new affinity mask: 1
위 예시에서는 2개의 CPU를 가진 시스템에서 1개의 CPU만 사용하도록 mask를 적용 한 것이다. 프로세스를 새로 띄우려면 아래와 같이 하면 된다.
$ sudo taskset <마스크> -- <프로그램>
affinity mask는 2진수 마스크로 가장 높은 자리가 마지막 논리 CPU를 의미하며 가장 낮은 자리가 첫 번째 논리 CPU로 지정하여 이를 16진수로 표기 한 것이다.
8개의 논리 CPU에 대한 마스크는 8자리
00000000
첫 번째와 두 번째 CPU
00000011 => 0x03
첫 번째와 마지막 CPU
10000001 => 0x81
모든 홀수 번째 CPU
01010101 => 0x55
모든 CPU
11111111 => 0xff
affinity mask를 16진수로 지정하는 부분은 사용자 친화적이지 않기 때문에 -c 옵션을 통해서 특정 CPU 번호를 지정 할 수도 있다.
$ sudo taskset -c 0,3,7-9 -- testprogram
2-2. numactl
taskset이 CPU affinity 설정을 위한 툴이라면 numactl 패키지에 포함되어있는 numactl 커맨드는 NUMA 정책을 설정하는 유틸리티이다.
2-2-1. NUMA 상태 확인
먼저 numactl의 –show(-s) 옵션을 통해서 현재 프로세스의 NUMA 정책을 볼 수 있다.
$ sudo numactl --show
policy: default
preferred node: current
physcpubind: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
cpubind: 0 1
nodebind: 0 1
–hardware(-H) 옵션은 현재 사용가능한 NUMA 노드 정보를 보여준다.
$ sudo numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 12 13 14 15 16 17
node 0 size: 65410 MB
node 0 free: 10950 MB
node 1 cpus: 6 7 8 9 10 11 18 19 20 21 22 23
node 1 size: 65536 MB
node 1 free: 10660 MB
node distances:
node 0 1
0: 10 21
1: 21 10
현재 NUMA의 운영 상태를 보기 위해서는 numactl 패키지에 포함된 numastat 커맨드를 통해서 확인 할 수 있다.
[서버 A]
$ sudo numastat
node0 node1
numa_hit 4537819602 4427659820
numa_miss 0 0
numa_foreign 0 0
interleave_hit 37568 37596
local_node 4537819489 4427618495
other_node 113 41325
[서버 B]
$ sudo numastat
node0 node1
numa_hit 18900017512 14587522385
numa_miss 6031138144 2662445985
numa_foreign 2662445985 6031138144
interleave_hit 18816 18826
local_node 18900011126 14587500303
other_node 6031144530 2662468067
각 항목의 의미를 살펴보면 다음과 같다.
![]()
numa_miss, numa_foreign이 높다는 것은 의도한대로 메모리가 할당되지 못하고 있다는 것을 의미하기 때문에 이를 줄이는 것이 보다 효율성을 높이는 방법이라고 할 수 있다. 앞서 본 예시에서 [서버 B]의 상태를 좀 더 다른 형태로 확인 해 보자. -m 옵션으로 메모리 정보(meminfo) 형태로 살펴보면 아래와 같다.
$ sudo numastat -m
Per-node system memory usage (in MBs):
Node 0 Node 1 Total
--------------- --------------- ---------------
MemTotal 16259.82 16384.00 32643.82
MemFree 880.89 55.18 936.07
MemUsed 15378.93 16328.82 31707.76
Active 8223.18 11994.76 20217.94
Inactive 6126.18 3857.87 9984.05
Active(anon) 5262.63 11008.37 16271.00
Inactive(anon) 1150.93 1104.14 2255.07
Active(file) 2960.55 986.39 3946.95
Inactive(file) 4975.25 2753.73 7728.98
Unevictable 0.00 0.00 0.00
Mlocked 0.00 0.00 0.00
Dirty 1.03 0.04 1.07
Writeback 0.00 0.00 0.00
FilePages 7936.11 3740.25 11676.36
Mapped 13.36 2.07 15.42
AnonPages 6411.74 12110.38 18522.12
Shmem 0.30 0.13 0.43
KernelStack 10.64 1.30 11.94
PageTables 16.93 28.00 44.93
NFS_Unstable 0.00 0.00 0.00
Bounce 0.00 0.00 0.00
WritebackTmp 0.00 0.00 0.00
Slab 435.75 108.10 543.85
SReclaimable 366.86 91.49 458.35
SUnreclaim 68.89 16.61 85.50
HugePages_Total 0.00 0.00 0.00
HugePages_Free 0.00 0.00 0.00
HugePages_Surp 0.00 0.00 0.00
실제 MemFree와 Active가 어느 노드에 더 집중되어있는지 비교해 볼 수 있다. 또한 특정 프로세스의 상태를 보고 싶다면 -p 옵션으로 해당 PID를 입력하거나 패턴문자를 통해서 확인이 가능하다.
$ sudo numastat -p mysql
Per-node process memory usage (in MBs)
PID Node 0 Node 1 Total
------------------ --------------- --------------- ---------------
1838 (mysqld_safe) 1.22 0.15 1.37
3628 (mysqld) 6390.69 12068.24 18458.93
------------------ --------------- --------------- ---------------
Total 6391.91 12068.39 18460.30
mysqld 프로세스가 Node 1에 메모리 리소스를 더 많이 사용하는 것을 확인 할 수 있다. -v 옵션을 주면 좀 더 상세한 정보를 확인 할 수 있다. (할당 영역)
$ sudo numastat -p mysql -v
Per-node process memory usage (in MBs) for PID 1838 (mysqld_safe)
Node 0 Node 1 Total
--------------- --------------- ---------------
Huge 0.00 0.00 0.00
Heap 0.11 0.06 0.17
Stack 0.00 0.01 0.02
Private 1.11 0.08 1.18
---------------- --------------- --------------- ---------------
Total 1.22 0.15 1.37
Per-node process memory usage (in MBs) for PID 3628 (mysqld)
Node 0 Node 1 Total
--------------- --------------- ---------------
Huge 0.00 0.00 0.00
Heap 32.08 445.15 477.23
Stack 0.00 0.07 0.07
Private 6359.44 11623.02 17982.46
---------------- --------------- --------------- ---------------
Total 6391.52 12068.24 18459.76
2-2-2. NUMA 정책 설정 (numactl)
numactl로 정책(policy)을 설정하고 프로그램을 실행하면 해당 프로그램의 프로세스는 numactl이 지정한 정책에 따라서 움직이게 된다. numactl의 옵션은 아래와 같다.
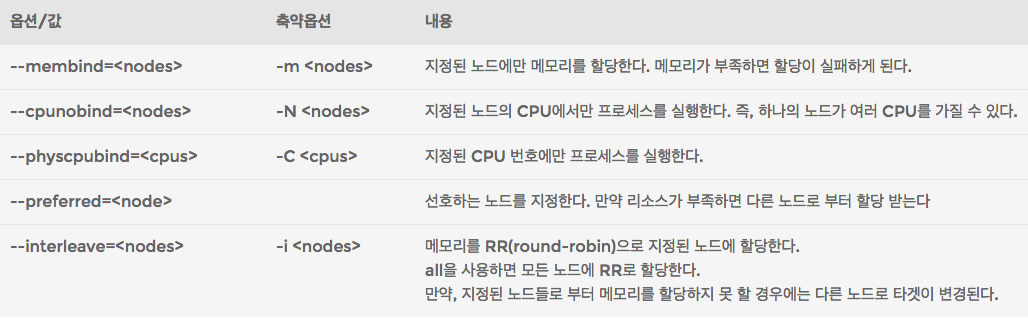
간단한 프로그램을 통해서 각 옵션별로 메모리 할당 상태를 확인해 보자. 프로그램 내용은 아래와 같다.
#include <stdlib.h>
#include <string.h>
int main(){
void *ptr;
long size = 40*1024*1024*1024ULL;
ptr = malloc(size);
memset(ptr, 0, size);
for(;;) { ; }
return 0;
}
테스트 시스템: 64GB 메모리를 가진 NUMA 시스템. 2개의 노드를 가지고 있다. (Haswell)
테스트 프로그램: 매우 단순하게 40GB 메모리를 할당 받아 무한 루프를 돈다.
먼저 해당 프로그램을 컴파일 하고 실행하기 전의 시스템 상태이다.
$ sudo numastat -c
Node 0 Node 1 Total
------ ------ -----
Numa_Hit 3396 3475 6871
Numa_Miss 0 0 0
Numa_Foreign 0 0 0
Interleave_Hit 100 100 200
Local_Node 3320 3410 6730
Other_Node 76 65 141
이제 해당 프로그램을 –membind=0 옵션을 주고 실행해 보자. 컴파일한 바이너리 이름은 malloc 이다.
$ sudo numactl --membind=0 -- ./malloc &
[1] 9249
$ sudo numastat -p malloc
Per-node process memory usage (in MBs) for PID 7870 (malloc)
Node 0 Node 1 Total
--------------- --------------- ---------------
Huge 0.00 0.00 0.00
Heap 0.00 0.00 0.00
Stack 0.00 0.00 0.01
Private 30866.64 0.29 30866.93
---------------- --------------- --------------- ---------------
Total 30866.64 0.30 30866.94
[1]+ Killed numactl --membind=0 -- ./malloc
메모리를 할당하다가 한쪽 노드의 메모리양(32GB)를 초과하여 프로세스가 죽어버렸다. (만약 시스템에 넉넉한 swap 공간이 있어서 swap을 포함한 메모리 공간이 충분하다면 프로세스가 죽지 않을 수도 있다) numa_miss로 찍힌 내용은 해당 프로그램이 아닌 다른 프로세스에 의해서 발생한 것이다. (해당 노드 메모리가 부족하여 다른 노드로 요청) 그리고, dmesg에는 아래와 같은 메시지가 남는다.
Out of memory: Kill process 9249 (malloc) score 870 or sacrifice child
이제 이 프로그램을 –preferred=0 옵션을 주고 실행 해 보자. 선호하는 노드의 메모리가 부족하면 다른 노드로 부터 메모리를 가져올 것이므로 프로세스가 죽지 않을 것으로 쉽게 예상 할 수 있다.
$ sudo numactl --preferred=0 -- ./malloc &
[1] 9823
$ sudo numastat -p malloc
Per-node process memory usage (in MBs) for PID 9823 (malloc)
Node 0 Node 1 Total
--------------- --------------- ---------------
Huge 0.00 0.00 0.00
Heap 0.00 0.00 0.00
Stack 0.01 0.00 0.01
Private 30355.08 10605.28 40960.36
---------------- --------------- --------------- ---------------
Total 30355.09 10605.28 40960.37
0번 노드로부터 최대한 메모리를 할당 받고 부족한 부분을 1번 노드로부터 받아왔음을 알 수 있다. 그리고, –cpunobind 옵션과 함께 지정한다면 가급적 해당 프로세스가 동작하는 노드의 CPU로부터 메모리 접근이 이루어지기 때문에 로컬메모리에 접근 할 확률이 높아지게 된다. 특정 프로세스가 모든 코어를 활용 할 것이 아니라면 이러한 방법(선호하는 노드 지정)도 좋은 전략이 될 수 있다.
이제 –interleaved=all 옵션을 주고 실행 해 보자.
$ sudo numactl --interleave=all -- ./malloc &
[1] 8506
$ sudo numastat -p malloc
Per-node process memory usage (in MBs) for PID 8506 (malloc)
Node 0 Node 1 Total
--------------- --------------- ---------------
Huge 0.00 0.00 0.00
Heap 0.00 0.00 0.00
Stack 0.01 0.00 0.01
Private 20480.04 20480.32 40960.36
---------------- --------------- --------------- ---------------
Total 20480.04 20480.33 40960.37
모든 노드에 고르게 메모리가 할당 된 것을 확인 할 수 있다. 따라서, interleave로 나누어진 메모리에 대한 접근은 로컬과 리모트의 평균 값에 해당하는 응답속도와 대역폭을 기대 할 수 있으며 일반적으로 하나의 노드가 보유한 로컬 메모리 크기 이상으로 메모리를 사용하는 어플리케이션에 유리 할 수 있다.
2-3. numad
앞서 살펴본 taskset, numactl의 경우 사용자가 직접 개입해서 특정 어플리케이션, 프로세스에 대한 리소스 할당 정책을 지정하는 관리 방법이다. 시스템의 리소스를 많이 사용하는 어플리케이션이 명확하고 소수라면 numactl을 통해서 지정하는 방법이 효과적 일 수 있지만 일반적으로 다수의 프로세스가 작업을 수행하는 환경에서는 이를 일일이 관리하는건 매우 어려운 일이다.
이를 위해 numad라는 사용자레벨의 서비스 데몬을 활용하는 방법을 살펴보자. numad는 현재 실행중인 프로세스에 대해서 리소스 사용 현황을 살피고 CPU, Memory에 대한 affinity를 조절하는 프로그램이다. 즉, numad는 아래 그림과 같이 특정 프로세스가 동일한 노드의 CPU와 메모리를 사용 할 수 있도록 조절한다.
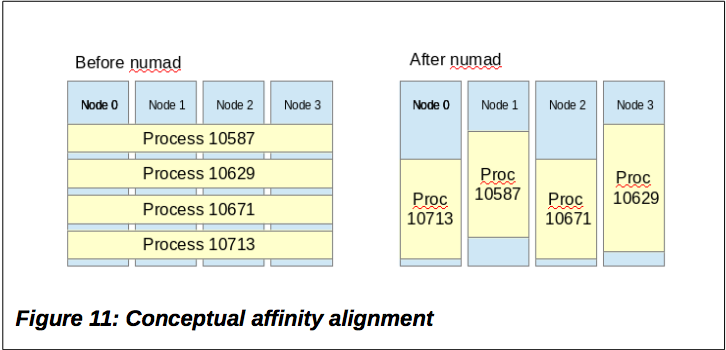
출처: RED HAT ENTERPRISE LINUX 7: OPTIMIZING MEMORY SYSTEM PERFORMANCE
앞서 설명한 것처럼 numad는 실행중인 프로세스가 동일한 NUMA 노드(CPU와 메모리가 같은 노드)에서 실행되도록 하기 때문에 일반적으로 하나의 시스템에 수십, 수백개의 어플리케이션이 실행되거나 여러 가상 게스트 시스템이 동작하는 집약적(Consolidation)인 시스템 환경에 적합하도록 되어있다. 따라서, 단일 어플리케이션이 많은 메모리 리소스를 사용하는 환경에서는 numad를 사용하기 보다는 해당 어플리케이션을 직접 numactl로 제어하는 편이 나을 수 있다.
2-2-2. 에서 사용했던 테스트 프로그램을 numad 환경에서도 테스트 해보도록 하자. numad 패키지를 설치했다면 서비스로 실행 할 수도 있지만 테스트 옵션을 쉽게 주기위해서 단독명령으로 실행하였다.
$ sudo lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 24
On-line CPU(s) list: 0-23
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Stepping: 2
CPU MHz: 2399.789
BogoMIPS: 4799.31
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 15360K
NUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18,20,22
NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,21,23
먼저, 노드 0번의 CPU 번호와 1번의 CPU 번호를 기억해두자.
$ sudo numad -i 15
$ ./malloc &
[1] 24191
$ ps -aF | grep mallo[c]
root 24191 7935 99 10486741 41943416 15 18:29 pts/0 00:04:12 ./malloc
먼저 별다른 옵션 없이 시스템 스캔 주기만 15로 주고 띄운 후에 프로그램을 실행 해 보았다. ps -aF 명령으로 확인 한 값의 7번 째 컬럼은 PSR 값으로 현재 할당 된 CPU ID가 찍힌다. 여기에서는 15로 확인되었고 앞서 살펴본대로 15번은 1번노드이다.
$ sudo numastat -p malloc
Per-node process memory usage (in MBs) for PID 24191 (malloc)
Node 0 Node 1 Total
--------------- --------------- ---------------
Huge 0.00 0.00 0.00
Heap 0.00 0.00 0.00
Stack 0.00 0.01 0.01
Private 9333.02 31627.34 40960.36
---------------- --------------- --------------- ---------------
Total 9333.02 31627.35 40960.37
1번 노드에 프로세스가 할당 되었기 때문에 메모리도 1번 노드부터 먼저 사용되고 있는 것을 확인 할 수 있다. 그리고 요구하는 메모리양이 노드를 넘어선 후 부터 옆 노드로 메모리 할당을 요청하게 된다.
numad에 적용가능한 몇 가지 옵션을 살펴보자.
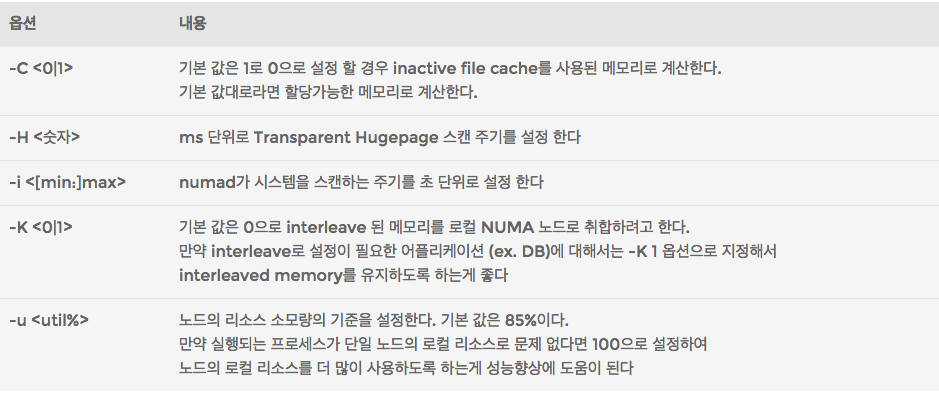
옵션 중에서 -K 옵션의 경우 numad가 기본적으로 프로세스가 실행되는 노드의 CPU와 메모리를 맞추려고 하기 때문에 interleave 된 메모리에 대해서 interleave 상태로 유지하도록 지정하는 옵션이다. 일반적인 상황에서는 별 문제 없지만 앞서 살펴봤던 단일 어플리케이션이 단일 노드 이상의 자원을 사용 할 경우 interleaved memory를 활용하는데 있어서 영향을 줄 수 있기 때문에 참고하자.
numad를 기본으로 실행하고 테스트하던 프로그램을 numactl을 통해서 interleaved memory로 할당해 보자.
$ sudo numad -i 1:5
$ sudo numactl --interleave=all ./mallc &
[1] 109091
$ sudo numastat -p malloc
Per-node process memory usage (in MBs) for PID 109091 (malloc)
Node 0 Node 1 Total
--------------- --------------- ---------------
Huge 0.00 0.00 0.00
Heap 0.00 0.00 0.00
Stack 0.00 0.01 0.01
Private 15176.32 25784.04 40960.36
---------------- --------------- --------------- ---------------
Total 15176.32 25784.05 40960.37
numactl로 interleave 설정을 하였음에도 불구하고 메모리를 할당하는 과정에서 중간중간에 1번 노드로 리소스가 더 많이 할당 되는 것을 볼 수 있다. 즉, interleaved memory를 최대한 로컬 노드로 할당하려고 numad는 영향을 주게 된다. 이제 numad를 -K1 옵션으로 설정하고 다시 실행 한 후에 프로그램을 실행 해 보자.
$ sudo numad -K1 -i 1:5
$ sudo numactl --interleave=all ./malloc &
[1] 109861
$ sudo numastat -p malloc
Per-node process memory usage (in MBs) for PID 109861 (malloc)
Node 0 Node 1 Total
--------------- --------------- ---------------
Huge 0.00 0.00 0.00
Heap 0.00 0.00 0.00
Stack 0.01 0.00 0.01
Private 20480.03 20480.33 40960.36
---------------- --------------- --------------- ---------------
Total 20480.04 20480.33 40960.37
numactl로 설정한대로 interleaved memory에 영향을 주지 않음을 확인 할 수 있다. 따라서, numad를 사용하는 환경에서 interleaved memory를 유지하려면 -K1 옵션을 켜고 사용해야 한다.
-H 옵션은 Transparent Hugepage에 대해서 스캔하는 주기를 설정하는 옵션으로 /sys/kernel/mm/tranparent_hugepage/khugepaged/scan_sleep_millisecs 에 설정된 10000ms를 1000으로 기본으로 바꾼다. THP를 사용하는 환경이라면 NUMA 노드간에 메모리 내용이 이동 되면 THP를 재구축해야하기 때문에 스캔 주기를 짧게 줄 수록 성능 향상에 도움이 된다.
-u 옵션은 노드의 최대 소비 비율(%)을 설정하는데 실행되는 프로세스가 단일 노드 자원으로도 충분하다면 이 값을 100으로 설정하여 각 노드의 자원 소비율을 최대로 높이는 것이 유리하다. 즉, 최대한 동일한 노드의 CPU와 메모리를 사용하도록 하는 것이다.
이외의 옵션들은 man numad를 참고하도록 하자.
2-4. Automatic NUMA Balancing
커널 3.8에서 Automatic NUMA Balancing(LWN 문서)에 대한 기능이 본격적으로 적용되었고 따라서, 3.10 커널을 기본으로 하는 RHEL/CentOS 7 부터는 해당 기능이 기본적으로 활성화 되어서 제공 되고 있다.
앞서 살펴본 유틸리티들이 사용자레벨에서 NUMA 정책을 설정하는 것이었다면 Automatic NUMA Balancing은 커널레벨에서 제공하는 기능이다. 간단히 설명하자면 주기적으로 프로세스의 메모리 매핑을 해제하고 메모리를 프로그램이 실행되는 노드로 옮기며 반대로 태스크를 메모리에 가깝게 옮기는 등의 기능을 수행한다. 기능적인 측면으로 볼 때 numad와 유사하다고 보면 되며 상세한 내용은 2014 Redhat Summit에서 발표 된 자료를 참고하자.
Automatic NUMA Balancing의 활성화 여부는 아래 커널 키 값으로 확인 해 볼 수 있다. NUMA를 지원하는 시스템이라면 기본 값이 1이다. (RHEL/CentOS 7 이상)
$ cat /proc/sys/kernel/numa_balancing
1
$ sysctl kernel.numa_balancing
kernel.numa_balancing = 1
해당 값을 0으로 변경하면 커널에서 제공하는 NUMA Balancing 기능은 비활성화 되게 된다.
2-5. 성능 비교
RED HAT ENTERPRISE LINUX 7: OPTIMIZING MEMORY SYSTEM PERFORMANCE 문서에서 제공하는 numactl, numad 그리고 Automatic NUMA Balancing의 비교 자료를 살펴보면
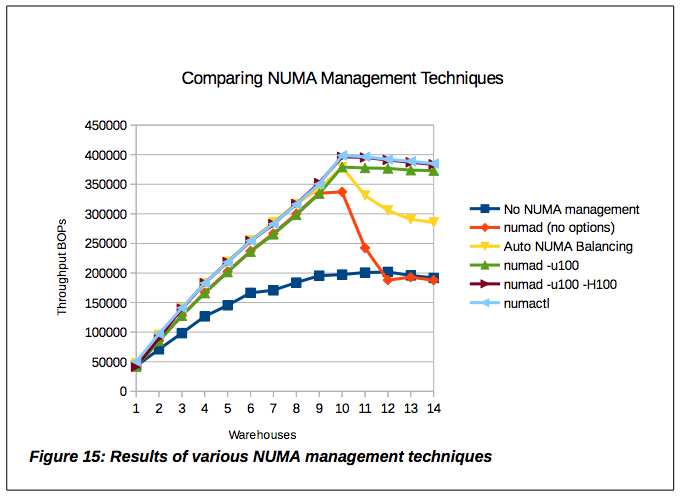
노란색 라인의 커널이 제공하는 Automatic NUMA Balancing도 나쁘지 않은 결과를 보이고 있다. NUMA에 대한 관리를 전혀 하지 않거나 numad를 기본으로만 띄운 것 보다 좋다. 그리고, 엔지니어/관리자가 수동으로 설정한 하늘색 라인(numactl)이 좋은 성능을 보이는 것으로 보이는데 이에 못지 않게 numad를 -u100, -H100 옵션을 주고 실행 한 경우도 결과가 좋다. 즉, 엔지니어/관리자가 직접 개입해서 설정하는 것도 좋지만 관리의 편의성을 고려한다면 numad의 옵션을 적절히 설정해서 운영하는게 좋다고 판단 된다.
2-6. 기타
numactl의 man page를 읽어봤다면 알겠지만 numactl에서(2.0.8 이상) 지정하는 노드 번호에 NUMA I/O Feature가 추가 되었다. 즉, 단순히 CPU에 대한 노드번호가 아니라 특정 네트워크 장치, IO 장치, 파일 등으로 지정이 가능하다. 이는 특정 프로세스가 I/O 처리를 할 때 사용되는 인터럽트, 메모리 데이터 등이 해당 I/O 장치와 연계된 노드로 할당하여 보다 나은 성능을 얻을 수 있도록 하기 위함이다.
3. 정리
NUMA는 멀티프로세서 환경에서의 성능 개선을 위한 방안으로 나온 구조이다. 절대적으로 완벽한 구조는 아니겠지만 잘 활용한다면 충분히 효과를 볼 수 있다. 앞서 살펴 본 내용을 토대로 아래와 같은 운영방법을 고려 해 볼 수 있다.
3-1. Node Interleaving vs numactl interleave
Node Interleaving
- 특정 어플리케이션이 전체 메모리의 과반 이상을 사용하는 경우 고려 해 볼 수 있지만 추천하지 않는다.
- 해당 어플리케이션 입장에서는
numactl --interleave=all과 거의 같은 결과일 수 있으나 - BIOS에서 설정한다면 전체적으로 떨어지는 응답속도를 해당 어플리케이션 뿐만 아니라 다른 프로세스들과 커널도 영향을 받는다.
interleaved memory가 필요한 어플리케이션을 numactl로 interleaved memory를 사용하도록 실행하는게 바람직하다.
3-2. numad
numad는 프로세스를 동일 노드에서 실행되도록 최선을 다하는 데몬
대량의 멀티프로세스 또는 다수의 싱글 프로세스 들이 많은 시스템에 적합
가상머신을 사용하는 환경에서도 가상 머신이 동일 노드 안에서 수행되도록 정렬하므로 유리함
단일 프로세스가 단일 노드 이상의 리소스 자원을 요구하고 사용할 때
- 어차피 단일 노드 이상의 리소스이므로 옆 노드로 메모리 할당이 발생 함
- 최대한 로컬 메모리 접근이 많이 발생 할 수 있도록 하기 때문에 나쁘지 않다
- 멀티스레드의 경우는 interleave가 유리 하다
- 프로세스가 메모리 리소스를 할당하고 스레드는 그 메모리를 공유하며 작업을 수행하는 경우 (ex. mongod)
- 즉, 다양한 스레드가 여러 노드에서 분산되어 실행 된다면 메모리가 모든 노드에 뿌려져 있는게 더 효율적임
- 3-3. interleaved memory 항목의 그림 참조
만약, interleave가 필요한 어플리케이션이 존재한다면 -K1 옵션을 주고 실행하자
커널 3.8 이상의 시스템에서는 Auto NUMA balancing이 있기 때문에 numad는 필요 없나?
- 좀 더 효율을 높이고자 한다면
numad -u100설정으로 운영하는 것을 권장
- 좀 더 효율을 높이고자 한다면
3-3. interleaved memory
interleaved memory가 만능 해결 책은 아니다
- 옆 노드에의 접근속도가 느리기 때문에 RR(round-robin)로 할당하는 메모리는 평균적으로 로컬보다 느리다
아래의 조건을 충족하는 경우에 효율적이다
- 단일 어플리케이션이 노드를 넘어서는 많은 메모리를 사용하는 경우
- 해당 어플리케이션이 싱글 프로세스가 아니라 멀티쓰레드 형태로 되어있는 경우
- 즉, 수 많은 쓰레드가 전체 노드의 CPU를 골고루 사용한다면 메모리가 흩어져있는 편이 낫다
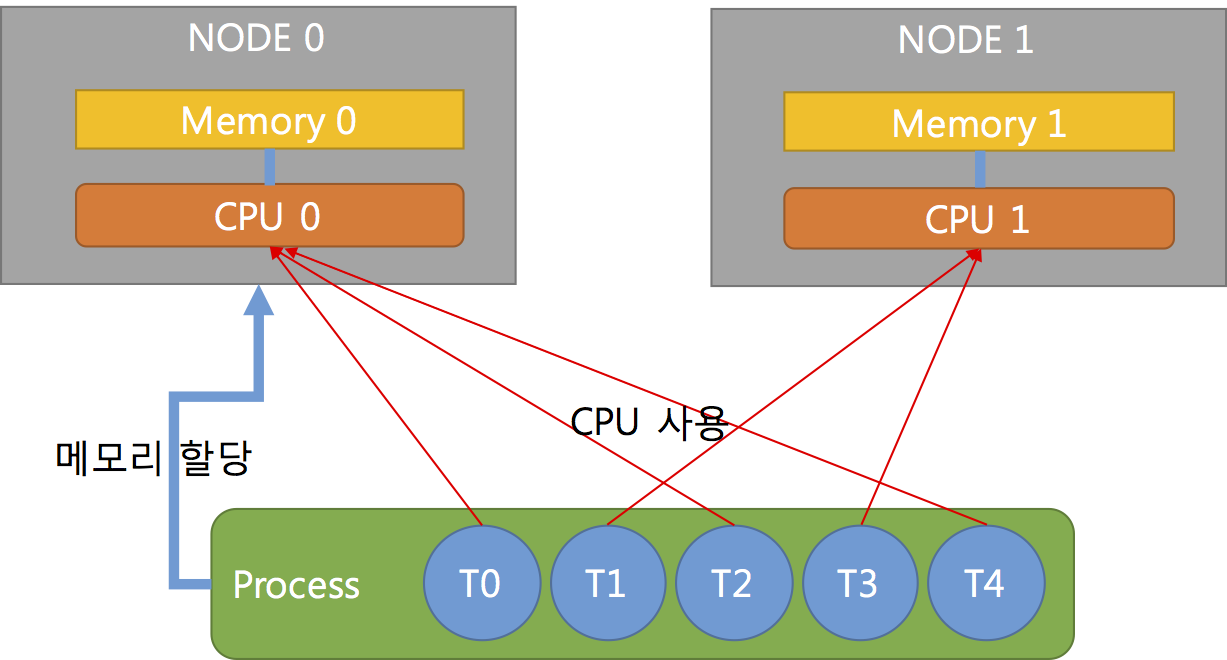
위의 그림처럼 프로세스가 NODE0에 있는 메모리(Memory 0)을 할당받아 사용하고 스레드는 여러 노드의 CPU에서 동작 될 때 CPU1을 사용하는 스레드는 공유하는 메모리가 다른 노드에 있기 때문에 응답속도가 CPU0를 사용하는 스레드보다 느리게 된다.
- 아래의 경우에는 interleaved memory 보다는 numad를 권장
- 싱글 프로세스 형태의 프로그램이 노드를 넘어서는 많은 메모리를 사용하는 경우
- 여러 프로세스의 노드 별 정렬이 중요 할 때 (ex. Hypervisor)
A. 추천 링크
아래는 NUMA와 관련된 추천 글에 대한 링크이다.
NUMA Deep Dive Series : 2016년 7월 10일 기준 연재 중 이며 NUMA 환경과 가상화(VMware) 환경에 대한 부분을 중점적으로 다루고 있다. 그림 정리도 좋기 때문에 적극 추천.
Mysteries of NUMA Memory Management Revealed: 본문에서 언급한 OPTIMIZING MEMORY SYSTEM PERFORMANCE 백서에 대한 글
Performance Analysis and Tuning 2014: Red Hat Summit 2014에서 발표된 자료. NUMA뿐만 아니라 전반적인 성능 튜닝에 대한 발표 자료.
Performance Analysis and Tuning 2015: Red Hat Summit 2015의 발표 영상.
High Performance I/O with NUMA Systems in Linux: Fusion IO에서 발표한 NUMA와 I/O에 대한 자료
NUMA Best Practices for Dell PowerEdge 12th Generation Servers: PDF 파일로 Dell 서버에서의 NUMA 및 NUMA I/O에 대해서 다루고 있다.