11 minutes
Load Average에 대하여
Load Average
본 문서는 Linux Load Average 값에 대해 소개하고 있습니다.
Load
Load Average는 말 그대로 Load 값의 평균을 나타낸 수치를 의미한다. 이를 이해하기 위해서는 먼저 Load가 무엇인지에 대해서 알아보는 것이 필요하다. 흔히, Load는 우리말로 ‘부하’로 표현된다. 부하라는 것의 사전적 정의를 보면 아래와 같다.
부하(負荷)
1.짐을 짐
2.[물리] 전기를 띠게 하거나 기계의 힘을 내게 하는 장치의 출력 에너지를 소비하는 일
3.일이나 책임을 맡김
- 출처: Daum 어학사전
Load에 대해서 거의 직역에 가깝게 표현했기 때문에 조금은 추상적이면서 모호한 표현이라고 볼 수 있다. 따라서, 사전적 의미로 접근하면 쉽게 이해되지 않을 수 있다. 앞으로 자세히 살펴보겠지만 먼저 개략적으로 정의를 하자면 Load는 Linux에서 특정 작업(Task)가 처리되는 과정에서 처리되기를 기다리는 정도를 표현 한 값으로 표현 할 수 있다.
Load에 대해서 좀 더 개념적인 이해를 위해서 이를 Linux에서 계산하는 과정에 대해서 자세히 살펴보도록 하자.
Process
프로세스는 흔히 작업(Task)으로도 불리운다. 어떠한 명령을 수행하기 위한 코드와 거기에 필요한 데이터 값의 덩어리를 객체로 표현한 것이 프로세스이다. 프로세스가 시스템에서 처리되기 위해서는 CPU(Processor) 연산을 필요로 한다. 하지만, CPU는 물리적으로 한정적인 자원이기 때문에 이를 특정 프로세스가 독점하지 못하도록 OS(Linux)는 프로세스 스케줄러(Scheduler)를 통해서 조절하게 된다. 멀티(Multi)프로세서는 CPU 자원이 1개 이상일 뿐이지 근본적으로 한정적 자원이라는 점에서는 변함이 없다.
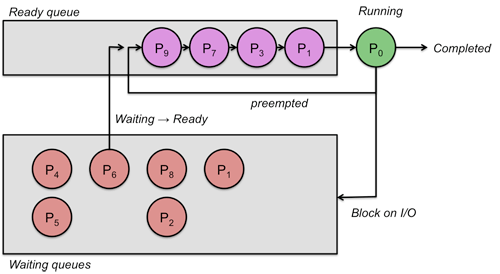 - 출처: cs.rutgers.edu
- 출처: cs.rutgers.edu
프로세스 스케줄러는 프로세스에 대한 디스크립터(기술자 - Descriptor)를 두고 관리를 하는데 프로세스 스케줄러에 의해서 관리되는 프로세스는 디스크립터에 아래와 같은 상태 값을 갖게 된다.

보다 더 많은 상태 값이 존재하지만 여기서는 생략하도록 한다. 커널 소스의 include/linux/sched.h 파일을 참조하자. 프로세스의 상태 값은 보통 아래와 같은 과정에 의해서 상태가 변경된다.
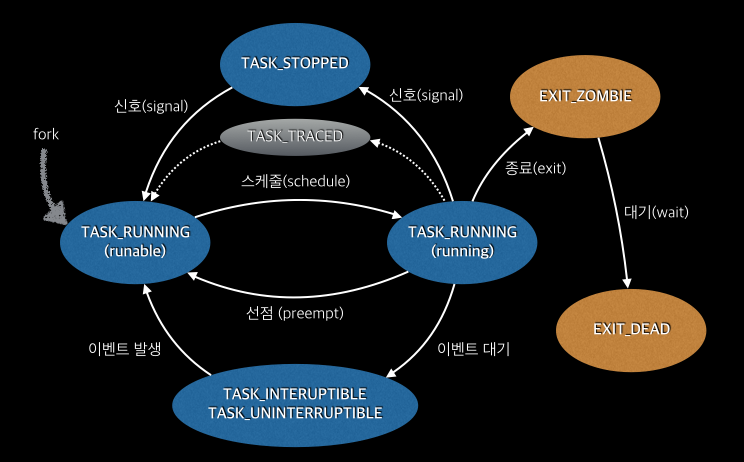
Process Scheduler
좀 더 구체적인 프로세스의 상태 변화를 살펴보도록 하자. 먼저 4개의 프로세스 A,B,C가 있고 각각의 프로세스는 아래와 같다.
- A: 복잡한 수식을 계산하는 프로세스 (우선순위가 보통)
- B: 사용자가 SSH를 통해서 접속한 Bash 프로세스 (우선순위 보통)
- C: 네트워크로부터 받은 데이터를 로그파일에 기록하는 프로세스 (우선순위가 가장 높음)
이제 각 프로세스가 순서대로 실행 되었을 때의 상태를 살펴보자.
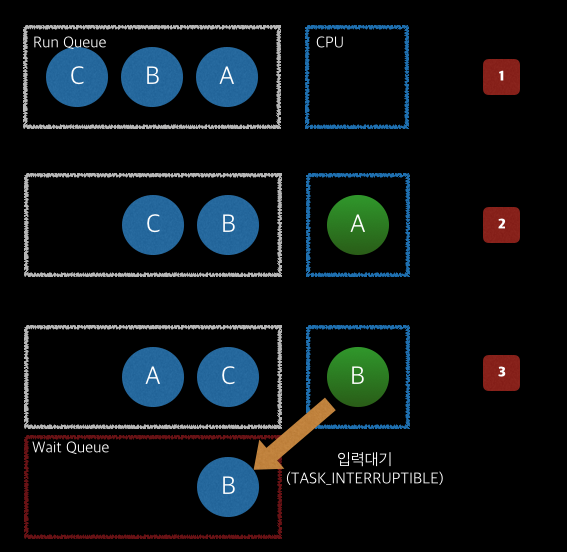
스케줄러에 의해서 A,B,C 프로세스는 순서대로 큐(queue)에 준비 된다. 각 프로세스는 막 실행되었기 때문에 TASK_RUNNING 상태를 갖고 있다. (1)
먼저, 스케줄러가 A 프로세스를 CPU에 할당하여 처리하도록 한다. 이 상황에서 여전히 프로세스 A는 B,C와 똑같이 RUNNING 상태이다. 차이점은 스케줄러에게 선택받아서 CPU 자원을 사용 중에 있다는 점이다. (2)
일정시간이 지나면 스케줄러는 타이머(timer)를 통해 A 프로세스를 중단시키고 다시 큐에 넣게 된다. 이제 B가 CPU를 사용할 차례가 온 것이다. (3)
하지만, B는 사용자가 터미널에 아무런 입력을 하고 있지 않기에 이내 곧 TASK_INTERRUPTIBLE 상태로 바뀌고 대기하게 되며 바로 C에게 CPU 사용 차례를 넘기게 된다. (3)
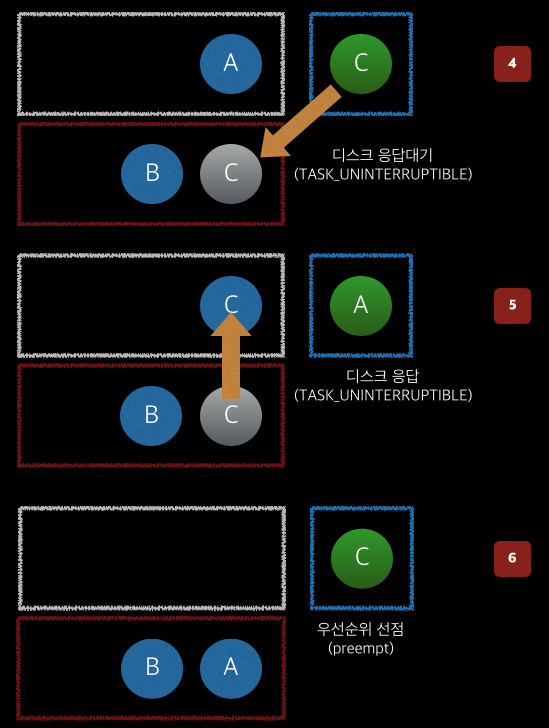
프로세스 C는 받은 데이터를 로그파일에 기록하기 위해서 파일 디스크립터에 데이터를 쓰게 된다. 이 과정에서 디스크로 부터 응답을 기다리게 되며 (실제로는 캐시 등에 의해서 바로 Write 작업에 대해 응답을 받기 때문에 대기하지는 않지만 본 예시는 이해를 돕기 위함이므로) TASK_UNINTERRUPTIBLE 상태로 바뀌게 된다. (4)
프로세스 스케줄러는 디스크 응답을 기다리고 있는 프로세스 C에서 프로세스 A에게 다시금 CPU 사용 권한을 주게 된다. (5)
프로세스 A가 CPU를 통해서 연산작업을 수행하고 있는 중에 프로세스 C가 디스크로부터 응답을 받고 TASK_RUNNING 상태로 바뀌며 스케줄러에 의해서 프로세스 C가 CPU 사용 권한을 획득하게 된다. (6)
실제 프로세스 스케줄러는 이보다 훨씬 더 복잡한 방식을 통해서 수행되지만 이해를 위한 간단한 예시라고 보면 된다. 이제 위의 과정에서 CPU 자원을 사용하기 위해서 각 프로세스가 기다렸던 시점을 생각해보자. 프로세스A가 CPU를 처음 사용 중일 때 B,C는 TASK_RUNNING 상태에서 자기 차례를 기다리고 있었으며 프로세스 B는 스케줄러에 의해 자기 차례가 왔지만 이내 사용자 입력을 기다리는 상태로 바로 차례를 넘기게 되었다. 이 때에도 프로세스 A,C는 차례를 기다리고 있었다. 프로세스 C 차례에서는 디스크에 기록한 데이터처리가 끝나기를 기다리게 되었고 이내 A에게 차례를 양보하게 되었다.
위의 예시를 보면 TASK_RUNNING 상태(CPU 사용중인 프로세스 제외)와 TASK_UNINTERRUPTIBLE 상태가 실질적으로 자기 차례가 되기를 기다리는 상태라고 볼 수 있는데 Load 값은 이 TASK_RUNNING과 TASK_UNINTERRUPTIBLE 상태에 있는 프로세스를 수치로 표현 한 값이다.
정리하면 처리를 위해서 기다리는 상태의 프로세스를 Load로 표현 한 것이다.
Load Average in Kernel
이제 커널에서 실제로 Load 값을 계산하는 부분을 찾아보도록 하자. 커널에서 Load Average를 계산하는 부분은 calc_load()라 불리우는 부분인데 이 함수 또한 사연(?)이 많다. 2.6 커널 이전에는 kernel/sched.c 파일에 있다가 2.6.18 커널에서는 kernel/timer.c 파일에 그리고 2.6.32 커널에서는 다시 kernel/sched.c로 돌아왔으며 calc_global_load() 함수가 호출하는 형태로 바뀌었다. 기존에 CALC_LOAD라는 매크로의 역할을 calc_load() 함수로 대체하고 calc_load()는 calc_global_load()로 바뀌었다고 보면 된다.
3.10 커널에서는 kernel/sched/core.c에 그리고 비교적 최근인 4.4 커널에서는 kernel/sched/loadavg.c 파일에 존재한다. 각 버전별로 해당 부분의 소스는 아래와 같다.
kernel 2.0.40 (kernel/sched.c)
static inline void calc_load(unsigned long ticks) { unsigned long active_tasks; /* fixed-point */ static int count = LOAD_FREQ; count -= ticks; if (count < 0) { count += LOAD_FREQ; active_tasks = count_active_tasks(); CALC_LOAD(avenrun[0], EXP_1, active_tasks); CALC_LOAD(avenrun[1], EXP_5, active_tasks); CALC_LOAD(avenrun[2], EXP_15, active_tasks); } }kernel 2.6.18 (kernel/timer.c - RHEL5)
static inline void calc_load(unsigned long ticks) { unsigned long active_tasks; /* fixed-point */ static int count = LOAD_FREQ; count -= ticks; if (count < 0) { count += LOAD_FREQ; active_tasks = count_active_tasks(); CALC_LOAD(avenrun[0], EXP_1, active_tasks); CALC_LOAD(avenrun[1], EXP_5, active_tasks); CALC_LOAD(avenrun[2], EXP_15, active_tasks); } }kernel 2.6.32 (kernel/sched.c - RHEL6)
void calc_global_load(void) { unsigned long upd = calc_load_update + 10; long active; if (time_before(jiffies, upd)) return; active = atomic_long_read(&calc_load_tasks); active = active > 0 ? active * FIXED_1 : 0; avenrun[0] = calc_load(avenrun[0], EXP_1, active); avenrun[1] = calc_load(avenrun[1], EXP_5, active); avenrun[2] = calc_load(avenrun[2], EXP_15, active); calc_load_update += LOAD_FREQ; }kernel 3.10 (kernel/sched/core.c - RHEL7)
void calc_global_load(unsigned long ticks) { long active, delta; if (time_before(jiffies, calc_load_update + 10)) return; /* * Fold the 'old' idle-delta to include all NO_HZ cpus. */ delta = calc_load_fold_idle(); if (delta) atomic_long_add(delta, &calc_load_tasks); active = atomic_long_read(&calc_load_tasks); active = active > 0 ? active * FIXED_1 : 0; avenrun[0] = calc_load(avenrun[0], EXP_1, active); avenrun[1] = calc_load(avenrun[1], EXP_5, active); avenrun[2] = calc_load(avenrun[2], EXP_15, active); calc_load_update += LOAD_FREQ; /* * In case we idled for multiple LOAD_FREQ intervals, catch up in bulk. */ calc_global_nohz(); }kernel 4.4 (kernel/sched/loadavg.c)
void calc_global_load(unsigned long ticks) { long active, delta; if (time_before(jiffies, calc_load_update + 10)) return; /* * Fold the 'old' idle-delta to include all NO_HZ cpus. */ delta = calc_load_fold_idle(); if (delta) atomic_long_add(delta, &calc_load_tasks); active = atomic_long_read(&calc_load_tasks); active = active > 0 ? active * FIXED_1 : 0; avenrun[0] = calc_load(avenrun[0], EXP_1, active); avenrun[1] = calc_load(avenrun[1], EXP_5, active); avenrun[2] = calc_load(avenrun[2], EXP_15, active); calc_load_update += LOAD_FREQ; /* * In case we idled for multiple LOAD_FREQ intervals, catch up in bulk. */ calc_global_nohz(); }
커널이 업그레이드 되면서 구현 방법이 조금씩은 바뀌었지만 근본적인 형태는 변하지 않았기 때문에 calc_global_load()가 있기 전 후에 해당하는 2.6.18 커널과 2.6.32 커널을 살펴보도록 하겠다. 이 두 커널은 위에도 표기한 것 처럼 RHEL5(CentOS5)과 RHEL6(CentOS6)의 근간이 되는 커널 버전이다.
먼저 2.6.18 커널의 count_active_tasks() 함수와 2.6.32 커널의 atomic_long_read 매크로가 불러들이는 calc_load_tasks값을 주목하자. 구현 방식은 다르지만 궁극적으로 해당 부분이 하는 역할은 현재의 Activ Task 개수를 계산하는데는 변함이 없다.
먼저 count_active_tasks()는 아래와 같다.
static unsigned long count_active_tasks(void)
{
return nr_active() * FIXED_1;
}
unsigned long nr_active(void)
{
unsigned long i, running = 0, uninterruptible = 0;
for_each_online_cpu(i) {
running += cpu_rq(i)->nr_running;
uninterruptible += cpu_rq(i)->nr_uninterruptible;
}
if (unlikely((long)uninterruptible < 0))
uninterruptible = 0;
return running + uninterruptible;
}nr_active() 함수의 결과를 가져와서 계산하는데 nr_active() 함수는 각각 nr_running(TASK_RUNNING)과 nr_uninterruptible(TASK_UNINTERRUPTIBLE) 상태의 프로세스 개수를 더해서 리턴하게 된다.
이제 calc_load_tasks 값을 저장하는 함수인 alc_load_account_active() 함수를 살펴보자.
static void calc_load_account_active(struct rq *this_rq)
{
long nr_active, delta;
nr_active = this_rq->nr_running;
nr_active += (long) this_rq->nr_uninterruptible;
if (nr_active != this_rq->calc_load_active) {
delta = nr_active - this_rq->calc_load_active;
this_rq->calc_load_active = nr_active;
atomic_long_add(delta, &calc_load_tasks);
}
}현재 프로세스 Run Queue(this_rq)에서 nr_running과 nr_uninterruptible의 값을 가져와서 더한다. 마찬가지로 TASK_RUNNING과 TASK_UNINTERRUPTIBLE 상태의 프로세스 개수를 구해오는 것이다. 즉, Active Task는 이 둘의 합을 의미하며 Linux 커널은 이 값을 주기적으로 계산해서 평균을 내고 그것을 1분,5분,15분 기준으로 표현한 값을 Load Average로 나타내는 것이다.
/proc/loadavg
앞서 살펴 본 계산을 통해서 구해진 Load Average 값은 /proc/loadavg 파일로 보여지게 된다. 이 파일의 내용을 보면 보통 아래와 같다.
$ cat /proc/loadavg
1.81 1.70 1.65 3/1179 39063총 5개의 데이터가 있으며 앞에서 부터 1분 평균, 5분 평균, 15분 평균, 큐 상태, PID를 나타낸다. 각각의 평균 값 외에 큐 상태와 PID 값이 있는데 이 값은 어떤 의미를 갖는지 알아보자. /proc/loadavg 값을 보여주는 부분은 fs/proc/loadavg.c에 있으며 아래와 같다.
static int loadavg_proc_show(struct seq_file *m, void *v)
{
unsigned long avnrun[3];
get_avenrun(avnrun, FIXED_1/200, 0);
seq_printf(m, "%lu.%02lu %lu.%02lu %lu.%02lu %ld/%d %d\n",
LOAD_INT(avnrun[0]), LOAD_FRAC(avnrun[0]),
LOAD_INT(avnrun[1]), LOAD_FRAC(avnrun[1]),
LOAD_INT(avnrun[2]), LOAD_FRAC(avnrun[2]),
nr_running(), nr_threads,
task_active_pid_ns(current)->last_pid);
return 0;
}여기에서 4번째 큐 상태의 의미를 확인 할 수 있다. 프로세스 스케줄러가 스케줄링한 전체 Task의 개수(nr_threads) 중에서 현재 실행 중인 Task의 개수(nr_running())를 보여주는 것이다. 그리고 마지막 PID 항목은 최근에 실행된 Task의 PID 값을 의미한다.
평균 계산 방법
경고
이 부분은 수학적인 계산식이 많이 나온다. 평균 값을 구하는 방법으로 통계학에서 자주 사용되는 (실제로는 주식시장 얘기에 더 많이 등장한다) 이동평균(Moving Average)과 지수평활법(Exponetial Smoothing)이 사용되는데 - 정확히는 지수감소이동평균(exponential-damped moving average) - 나처럼 수학적으로 이해하는데 어려움이 있다면 다음 문장만 생각하고 이 단락을 건너 뛰어도 좋다.
- 모든 Load 값을 저장하고 평균을 낼 수 없기 때문에 과거 시점의 평균 값을 토대로 현재의 평균 값을 계산하는 방법을 사용한다. 이러한 방법은 평균 그래프 등을 그릴 때도 자주 사용된다.
계산 방법
앞서 살펴 본 대로 Load는 처리를 대기하는 Task(프로세스)의 개수를 의미하는데 이 값을 평균내는 방법에 대해서 간단히 살펴보도록 하자.
특정한 값에 대해서 평균을 내기 위해서는 일반적으로 전체를 더한 뒤에 개수로 나눈 값으로 표현한다. 하지만, 이러한 방법은 모든 값을 전부 저장하고 있어야 하기 때문에 한정적인 자원에서는 사용하기가 어렵다. 그렇기 때문에 특정 시점의 평균 값을 이전 시점의 평균 값을 참고하여 계산하는 방법을 사용하게 되는데 Linux에서는 지수이동평균(EMA: Exponetial Moving Average) 방식을 바탕으로 Load Average를 구하고 있다. 지수감소이동평균을 통해서 계산하는 수식은 아래와 같다.
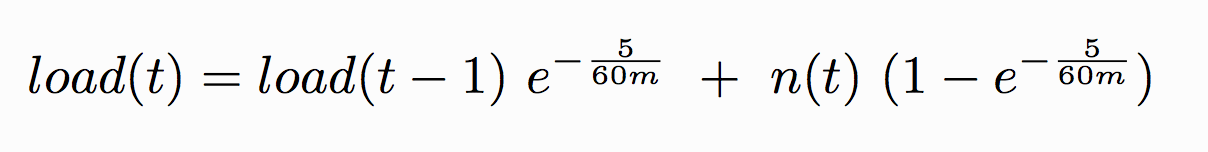
- m: 리포팅을 위한 시간 (1분, 5분, 15분 등)
- load(t): 현재의 Load 값
- load(t-1): 지난 Load 값
- n(t): 현재의 Active Task 개수
이 수식이 의미하는 바를 이해하기 위해 커널 코드를 참조해 보자. 먼저 커널 코드에서 sched.h 파일의 #define 부분을 살펴보면 아래와 같다.
/*
* These are the constant used to fake the fixed-point load-average
* counting. Some notes:
* - 11 bit fractions expand to 22 bits by the multiplies: this gives
* a load-average precision of 10 bits integer + 11 bits fractional
* - if you want to count load-averages more often, you need more
* precision, or rounding will get you. With 2-second counting freq,
* the EXP_n values would be 1981, 2034 and 2043 if still using only
* 11 bit fractions.
*/
extern unsigned long avenrun[]; /* Load averages */
#define FSHIFT 11 /* nr of bits of precision */
#define FIXED_1 (1<<FSHIFT) /* 1.0 as fixed-point */
#define LOAD_FREQ (5*HZ+1) /* 5 sec intervals */
#define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */
#define EXP_5 2014 /* 1/exp(5sec/5min) */
#define EXP_15 2037 /* 1/exp(5sec/15min) */
#define CALC_LOAD(load,exp,n) \
load *= exp; \
load += n*(FIXED_1-exp); \
load >>= FSHIFT;주석에서는 Load Average를 구하기 위해서 고정소수점 방식을 사용하고 11비트의 소수자리를 사용하는 것을 알 수 있다. FSHIFT는 쉬프트 연산을 위해 11의 값을 갖게 되고 1.0을 의미하는 값 FIXED_1은 1을 11비트 쉬프트(shift) 하여 표현하게 된다. (즉, 일반정수라면 2048 = 2^11을 의미하겠지만 고정소수점이기에 1.0이 된다)
EXP_1의 값이 나오게 된 원인을 찾아보자. 먼저 Load Average를 계산하는데 있어서 지수이동평균의 감소인수(damping factor) 값은 e^-(5/60m)이다. 이를 다시 표현하면 주석에 나와 있는대로 1/e^(5/60m)이다. 여기에서 EXP_1은 1분에 대한 값이기 때문에 m은 1이 되고 아래와 같이 표현할 수 있다.
1) 1 / e^(5/60m)
2) m = 0
3) 1 / e^(5/60)
4) e^(-(5/60))
이제 e^(-(5⁄60)) 값을 구해보도록하자. 간편하게 python을 실행해서 math 모듈을 이용해서 계산해 보았다.
>>> import math
>>> e = math.exp(-(5.0/60.0))
>>> print e
0.920044414629이 값을 고정소수점으로 표현하기 위해서 앞서 계산한 변수 e에 다가 2^11(2048)을 곱해보자. (고정소수점 표시를 위해 11자리를 SHIFT 했던 것을 기억하자)
>>> e * 2048
>>> 1884.2509611608541884.250961160854가 나왔는데 소수점을 버리면 EXP_1인 1884가 된다. 즉, 고정소수점 연산을 위해서 미리 계산된 감소인수 값이다. 마찬가지로 1분 대신 5분, 15분에 대해서 값을 대입해보면 2014, 2037의 값을 얻을 수 있다.
이제, CALC_LOAD 매크로를 다시 풀어서 살펴보면 맨 처음에 봤던 수식과 동일 한 것을 알 수 있다.
load*exp + n*(FIXED_1 - exp)
= load(t-1)*e + n(t)*(1 - e)
e는 감소인수(= e^(-5/60))를 간략히 쓴 것이다
기타
앞에서 살펴 본 주석에서도 설명하고 있듯이 5초(LOAD_FREQ)를 기준으로하여 EXP_1, EXP_5, EXP_15 값이 고정적이므로 주기를 더 짧게 하기 위해서는 EXP_n 값도 같이 맞춰서 변경 해 주어야 한다. 또한, 최근 커널의 경우 앞에서 살펴 본 계산식에 대한 구현을 조금 달리 하고 있으며 이는 보다 정확한 값을 얻기 위함이라고 생각하면 된다.
Load Average 판단
Load Average는 Active Task의 평균 값을 의미한다고 확인했다. 그렇다면 이 Load Average는 어떤 값일 때 정상이라고 봐야 할까? 이 문서에서는 Load Average를 교통량에 비유하여 쉽게 설명하고 있다.
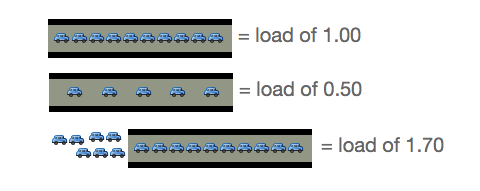 - 출처: scoutapp
- 출처: scoutapp
1개의 차선(1 CPU 또는 Core)에 차가 문제 없이 지속적으로 지나갈 때를 1로 보고 있기 때문에 전체 시스템의 CPU(또는 Core) 개수 만큼의 Load 값에 대해서는 문제가 없다고 판단한다. 다시 말해 CPU 마다 처리를 기다리는 프로세스가 1개씩 있을 경우에는 큰 문제가 없다고 판단하는 것이다.
하지만, Active Task에는 TASK_UNINTERRUPTIBLE이 있기 때문에 주의 할 필요가 있다. 특정 프로세스가 장시간 I/O를 점유하고 있으면 같은 자원을 사용하려는 다른 프로세스의 I/O 처리를 위한 대기시간에 크게 영향을 미치기 때문에 겉으로 보기에는 Load Average가 높지 않지만 실제 시스템에서 I/O 및 Buffer를 거치는 작업 등에서 지연을 경험 할 수도 있다. 반대로 Load Average가 높지만 다른 프로세스와 동일한 자원을 사용하지 않는 I/O 처리 대기나 프로세스 간에 Context switching이 원활 할 경우에는 성능저하가 별로 느껴지지 않을 수도 있다.
게다가 Load Average는 단순히 Active Task의 평균 값이기 때문에 시스템이 갖고 있는 CPU 개수에 따라서 그 의미가 달라지게 된다. 즉, 절대적인 기준 값을 잡기에는 어려움이 존재한다.
과거 Unix의 경우에는 TASK_RUNNING의 개수만을 Load Average 계산 대상으로 보았고 Linux에서는 좀 더 현실성있는 수치로 만들기 위해 TASK_UNINTERRUPTIBLE을 추가하였지만 여전히 Load Average는 절대적 기준을 두기에는 무리가 있는 수치라고 보여진다.
정답은 없겠지만 개인적인 판단으로는 CPU(Core)의 개수를 기준으로 두고 비율을 계산했을 때 100%가 되지 않도록 유지하는 것이 좋다고 본다. 예를 들어 Quad Core(4 Core) CPU 1개가 있는 시스템에서 Load Average가 3이라면 75%의 사용률이라고 볼 수 있기 때문에 3이하로 유지할 수 있도록 하는 것이 좋다고 생각한다. 앞서 이야기 한 것처럼 TASK_UNINTERRUPTIBLE 상태의 프로세스도 있을 수 있으므로 단순히 Load Average로만 판단하기 보다는 procps의 다양한 툴들(top, vmstat, slabtop 등)과 다른 모니터링 툴의 수치도 참고하여 판단하는 것이 좋다.
요약
- Load Average는 Active Task(TASK_RUNNING, TASK_UNINTERRUPTIBLE) 개수의 평균 값이다
- 일반적으로 CPU(Core)개수보다 Load Avearge 값이 적으면 문제가 없지만 상황에 따라 다를 수도 있다
- 여타 모니터링 데이터가 그러하듯이 Load Average 만으로 시스템 부하를 판단하지 않는 것이 좋다
참고문헌
- 본문의 링크
- Linux Load Reveald, CMG Conference 2004
- Understanding load averages and stretch factors STRETCH (http://linux-magazine.com)
- Load - Wikipedia
- CPU Load Averages - Julia Evans
- Analyzing Computer System Performance with Perl - Neil J. Gunther
p.s: Load Average에 대해서 쉽게 써보려고 했으나 결과적으로 망했다고 생각한다.